随着深度学习模型的不断增大、数据的不断增多,并行计算成为了解决机器学习训练难题的一种主流技术。本文主要是对Shusen Wang的《分布式机器学习》课程的笔记记录和扩展,仅是对机器学习中并行计算方式的概述。
概述
什么是并行计算?
使用多个处理器来加速计算过程,使时钟运行时间更短 多个处理器的情况包括
- 一台计算机上有多个CPU
- 多个计算机的CPU
为什么机器学习中需要并行计算?
- 深度学习模型大。模型参数越来越多
- 训练数据多。比如ImageNet有14M张图片
- 计算资源成本高。在大模型上训练大数据集的必然结构
并行计算与分布式计算
分布式计算可以看做是一种并行计算。两者的界限是模糊的,但从机器学习研究人员角度出发
并行计算 Parallel computing
- 数据或模型被分划分成多份,但这些CPU都属于一台电脑,并行计算任务仍在一台电脑节点执行
分布式计算 Distributed computing
- 数据或模型被分划分成多份,且在不同的节点上进行计算
房价预测实例
线性预测器
输入:\(X \in \mathbb{R}^d\)(有关房价的特征)
预测:\(f(X) = X^T W\)(房价)
- 假设有\(d\)个房价相关的特征,如面积、年限等
- \(f(X) = w_1x_1 + w_2x_2 + w_3x_3 + \cdots + w_dx_d\)
- 其中\(x_i\)表示特征,\(w_i\)是其权重
训练模型
训练集
- 输入:\(X_1, \cdots, X_n \in \mathbb{R}^d\)
- 标签:\(y_1, \cdots, y_n \in \mathbb{R}\)
损失函数:\(L(\mathbf{W})=\sum_{i=1}^{n} \frac{1}{2}\left(\mathbf{X}_{i}^{T} \mathbf{W}-y_{i}\right)^{2}\)
最小二乘回归:\(\mathbf{W}^{*}=\underset{\mathbf{W}}{\operatorname{argmin}} L(\mathbf{W})\)
梯度下降:
- 梯度:\(g(W)=\frac{\partial L(\mathrm{W})}{\partial \mathrm{W}}=\sum_{i=1}^{n} \frac{\partial \frac{1}{2}\left(\mathbf{X}_{i}^{T} \mathrm{W}-y_{i}\right)^{2}}{\partial \mathrm{W}}=\sum_{i=1}^{n}\left(\mathbf{X}_{i}^{T} \mathbf{W}-y_{i}\right) \mathbf{X}_{i}\)
- \(g(\mathbf{W})=\sum_{i=1}^{n} g_{i}(\mathbf{W}), \text { where } g_{i}(\mathbf{W})=\left(\mathbf{X}_{i}^{T} \mathbf{W}-y_{i}\right) \mathbf{X}_{i}\)
- \(W_{t+1} = W_t - \alpha \cdot g(W_t)\)
我们可以发现,当仅一个处理器处理大的模型`和海量数据的时候,计算量是巨大的。
并行梯度下降训练
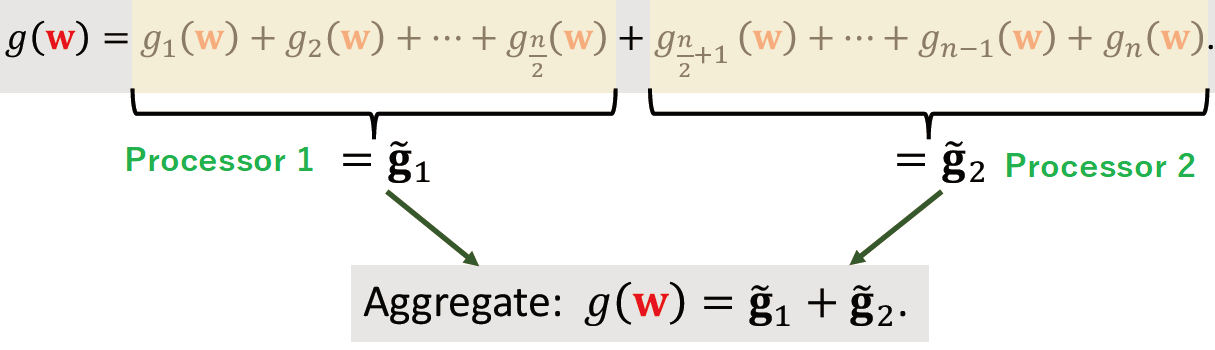
并行梯度下降的基本思想便是利用多个处理器来分别利用自己的数据计算梯度,最后通过聚合或其他方式来实现并行计算梯度下降以加速模型训练过程。 下面的图示便展示了两个处理器各自利用一半数据计算梯度\(\tilde{g}_1\)、\(\tilde{g}_2\),然后将两个结果进行聚合,实现了并行梯度下降:
概念
通信 Communication
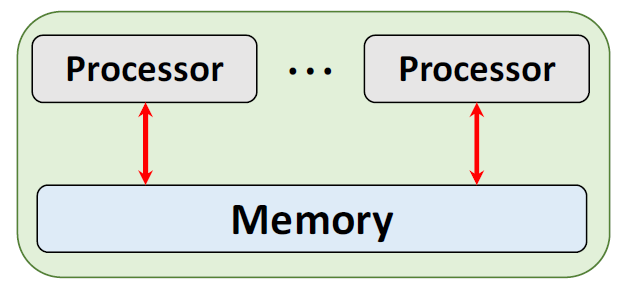
内存共享 Share memory
当处理器共用一个内存,它们可以访问相同的数据,直接进行通信
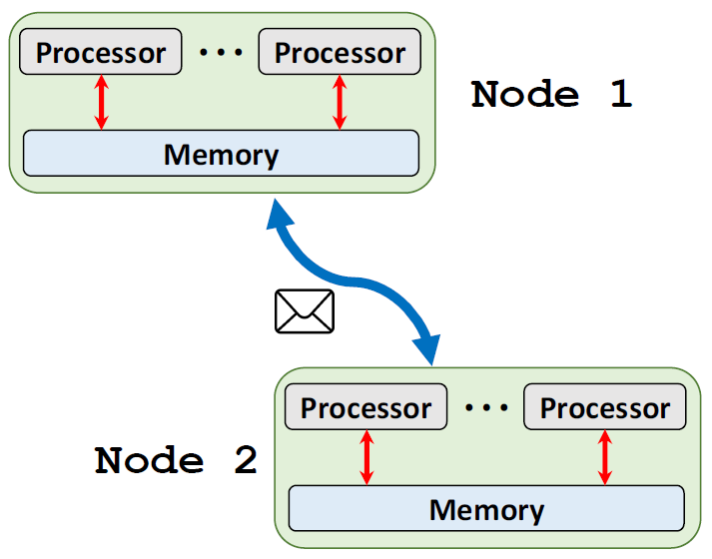
消息传递 Message passing
当存在多个节点的时候,不同节点上的处理器所访问的内存是不同的。这种情况下,需要通过消息传递来进行通信
架构 Architecture
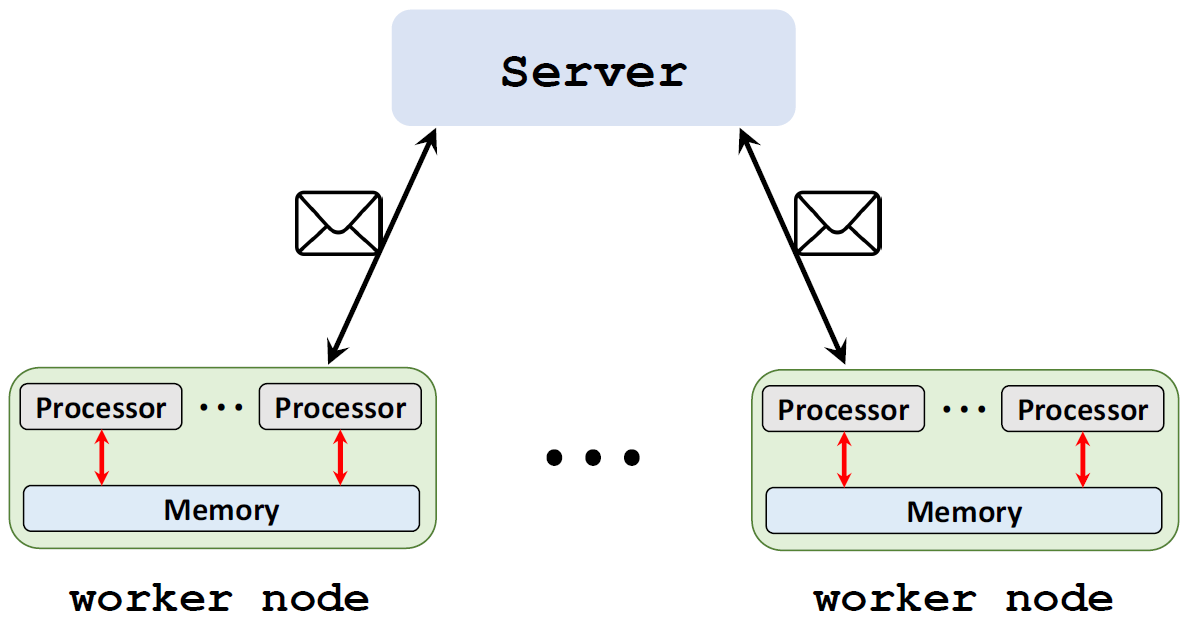
Client-Server
一个节点作为Server来协调其他节点,其他节点作为Worker来执行计算任务
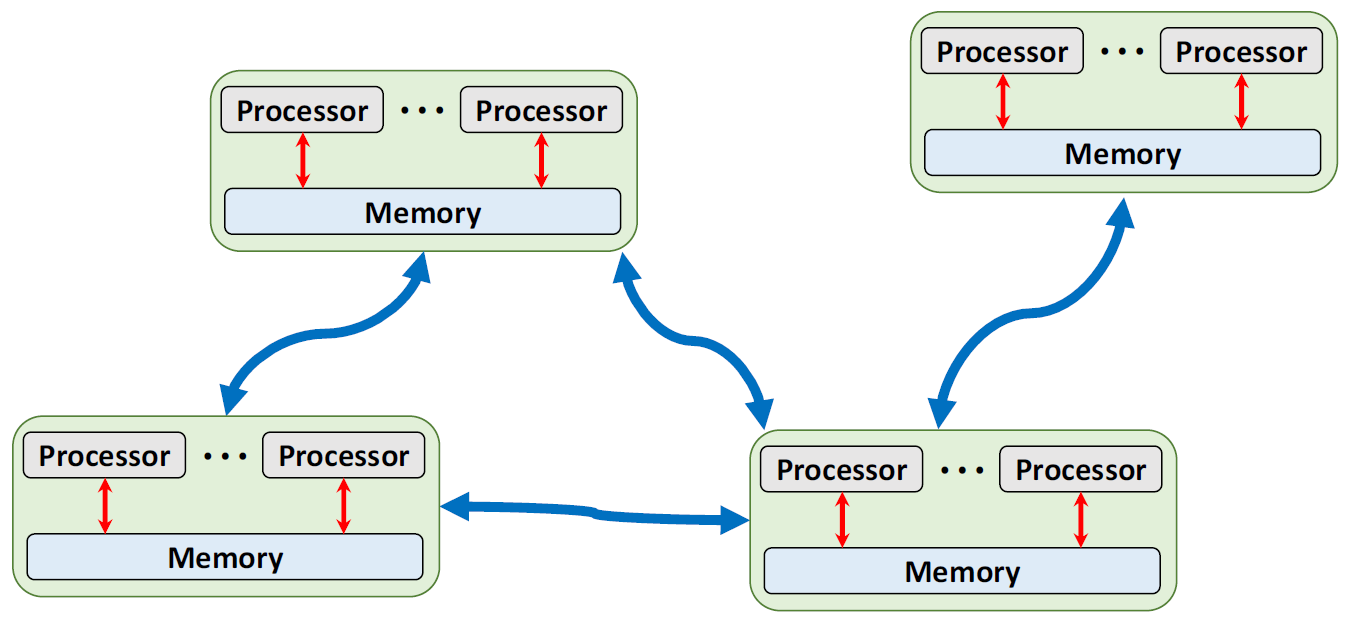
Peer-to-Peer
每个节点都是平等的,它们都有邻居,邻居之间可以通信
同步性
批同步 Bulk Synchronous
当全部Worker节点发送梯度信息到Server后,Server才进行一次参数更新
异步 Asynchronous
当一个Worker将计算出的梯度传回Server时,Server随即进行一次参数更新
并行性 Parallelism
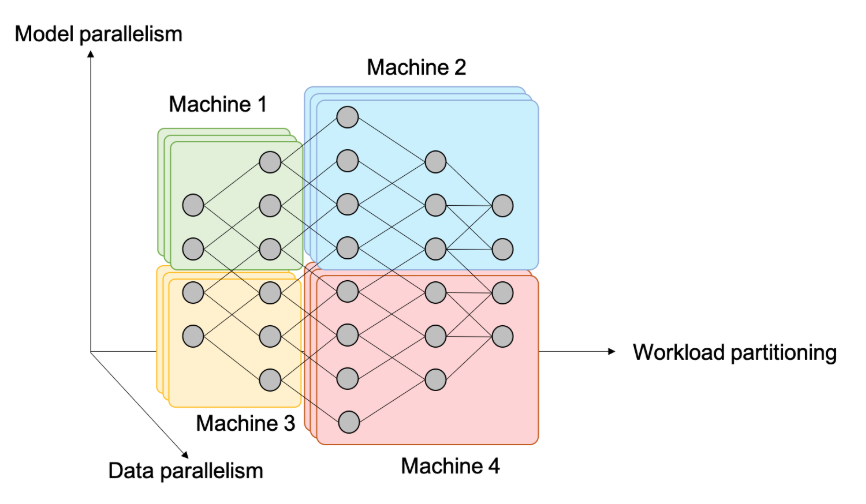
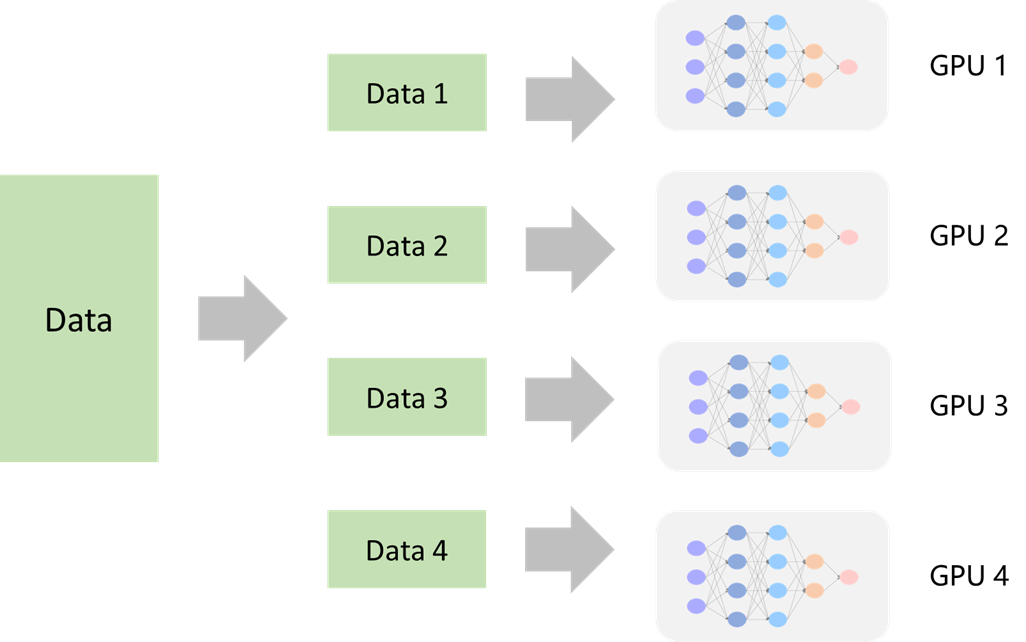
数据并行
这是主流的并行方式。将数据划分成若干份,分别在拥有整个模型的Worker上进行梯度计算,不同Worker间梯度计算是并行的
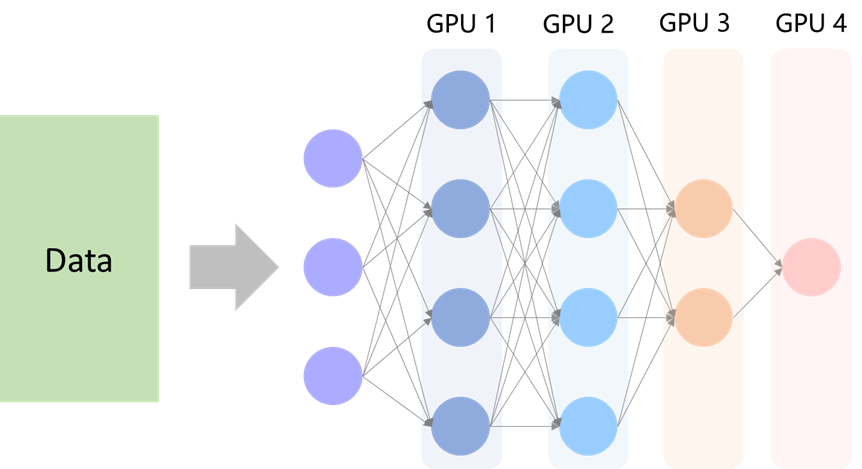
模型并行
当模型太大了以致于不能把整个模型载入一个GPU中,可以考虑把整个模型按层或其他方式分解成若干份。
- 比如每个不同的节点计算着整个模型的不同的层,计算着不同的层的梯度。
- 模型较后部分的计算必须等前面计算完成,因此不同节点间的计算实际是串行的。但每个部分计算互不妨碍,更像是流水线结构
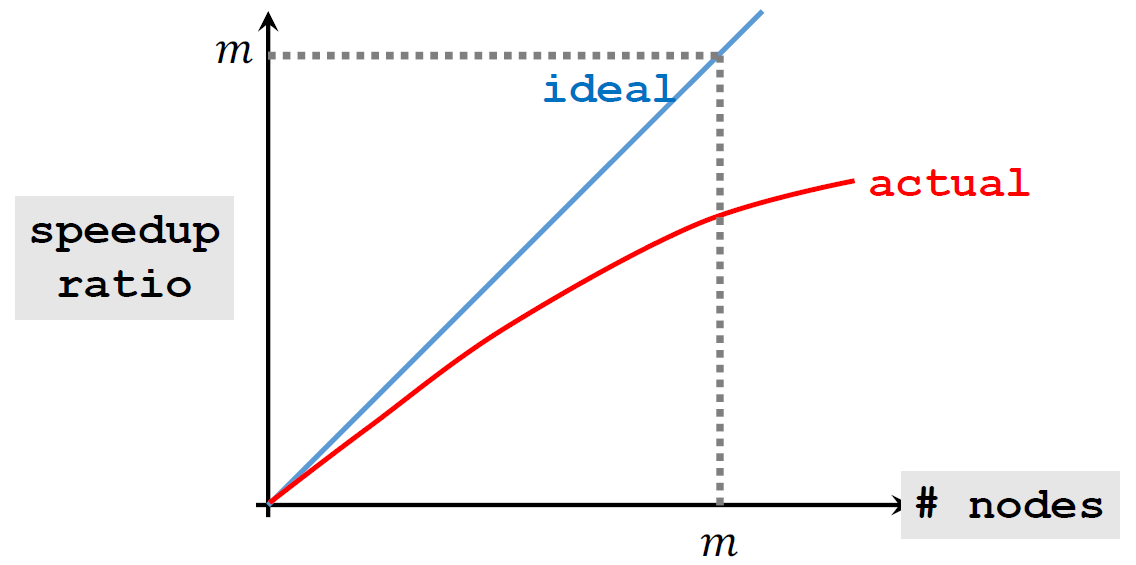
成本与加速比 Cost & Speedup Ratio
\[加速比 = \frac{使用一个节点消耗的时钟时间}{使用m个节点消耗的时钟时间}\]
实际加速比是低于\(m\)倍的:存在其他成本,如通信和同步
计算成本
节点执行计算任务所消耗的时间,与模型大小、数据量和节点计算性能有关。
通信成本
数据传输所消耗的时间,通常由通信复杂度和延迟所决定 \[T = \frac{\text{complexity}}{\text{bandwith}} + \text{latency}\]
通信复杂度
- 即Server与Worker传输的数据大小
- 随模型参数量和Worker节点数量增加而增长
延迟
- 数据传输时可能会产生延迟
- 取决于计算机网络状况
同步成本
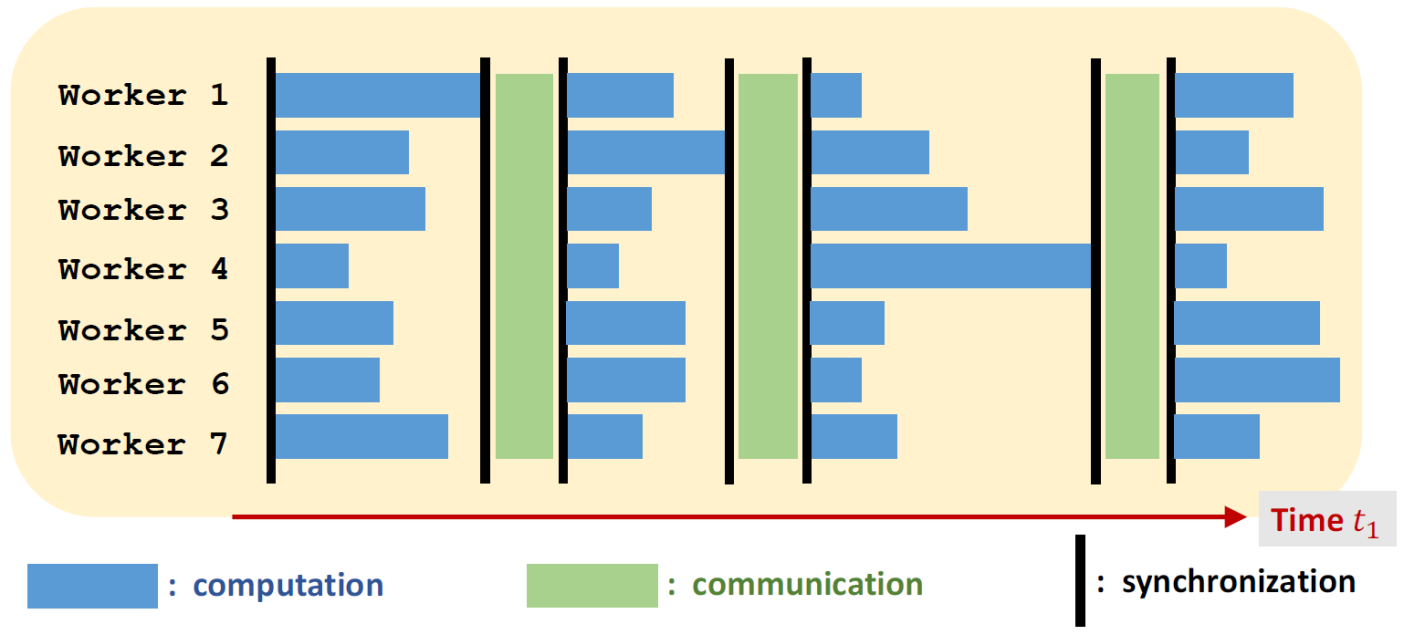
当采用同步的计算方法时(如MapReduce),就可能会产生同步成本,因为不同节点完成相同任务的时间可能是不同的。 Stragger节点
- 一个严重慢于其他节点的Worker,比如因为特殊情况而重启
- 同步并行计算方法实际时钟时间消耗取决于最慢的节点
主流框架
| 通信 | 架构 | 并行性 | |
|---|---|---|---|
| MapReduce | Message passing | client-server | synchronous |
| Parameter Server | Message passing | client-server | asynchronous |
| Decentralized | Message passing | peer-to-peer | synchronous or asynchronous |
MapReduce
由Google提出
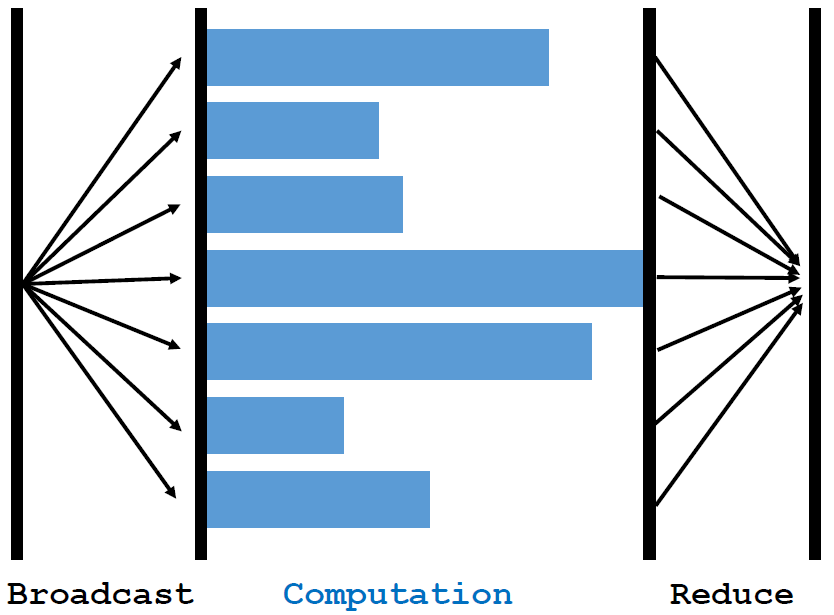
- 本质思想:Server广播参数,Worker执行Map运算并将结果返回Server,Server执行Reduce,从而完成一次参数更新
- 开源实现:Hadoop、Spark等
框架特点
- 架构:client-server
- 通信:消息传递
- 并行方式:批量同步
计算流程
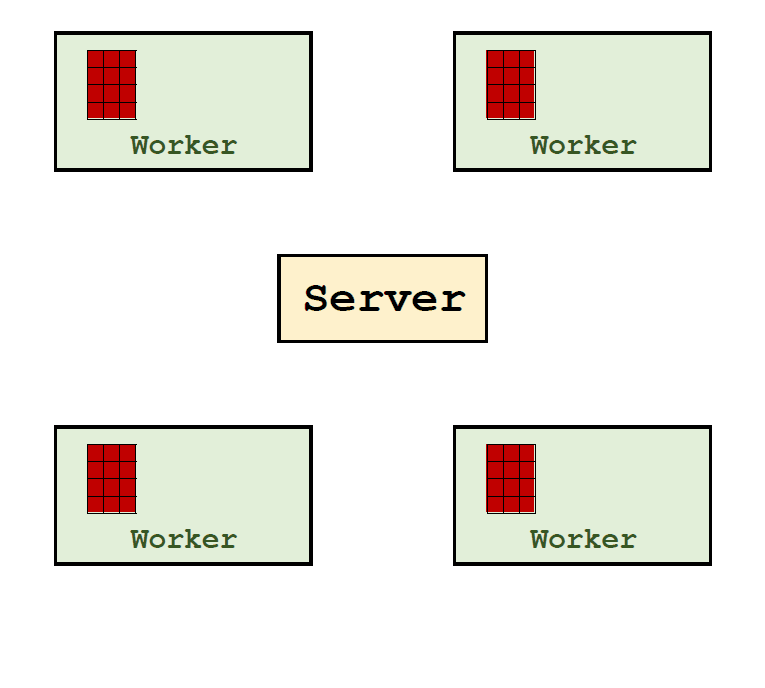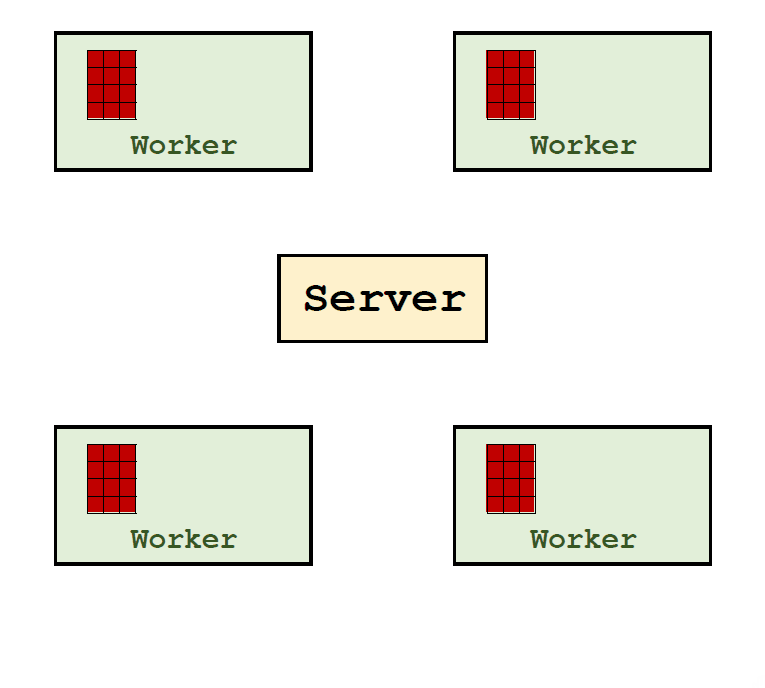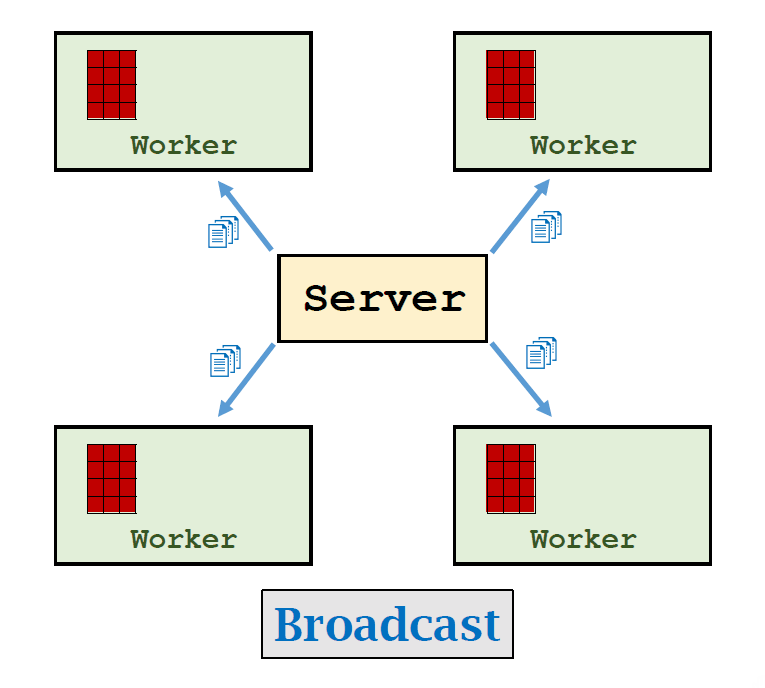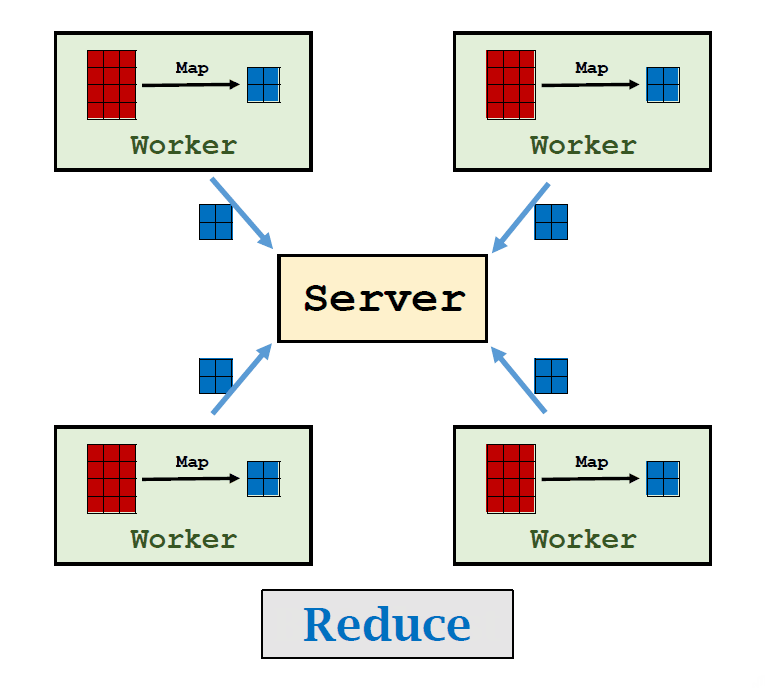
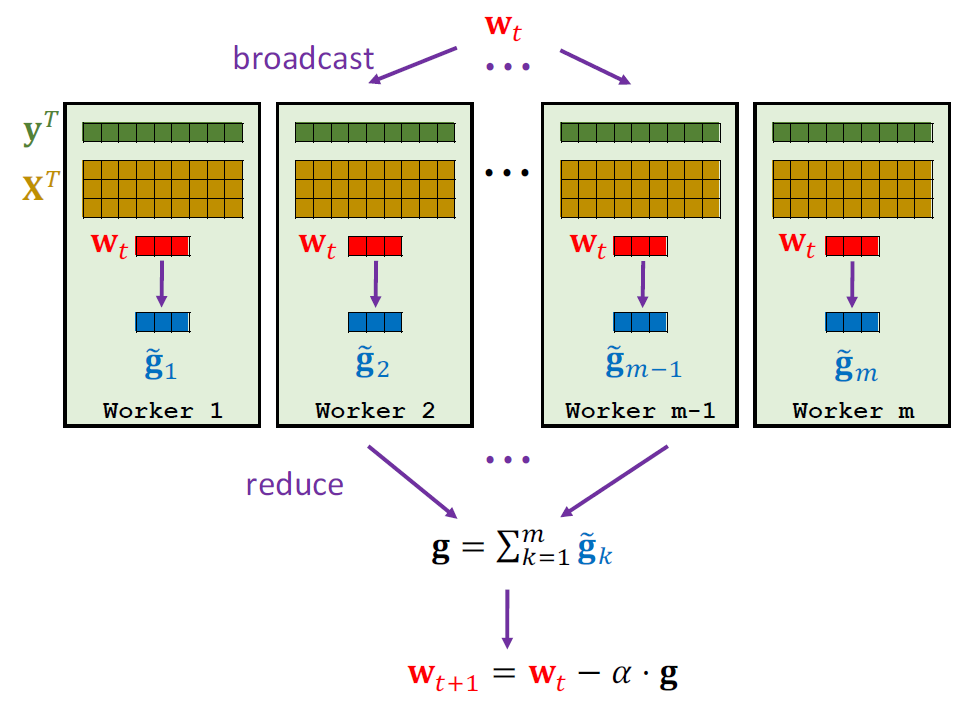
Broadcast:Server将参数发送给每个WorkerMap:每个worker利用自己的数据进行Map操作Reduce:Worker将Map后的结果发送到Server,Server进行Reduce操作
梯度下降
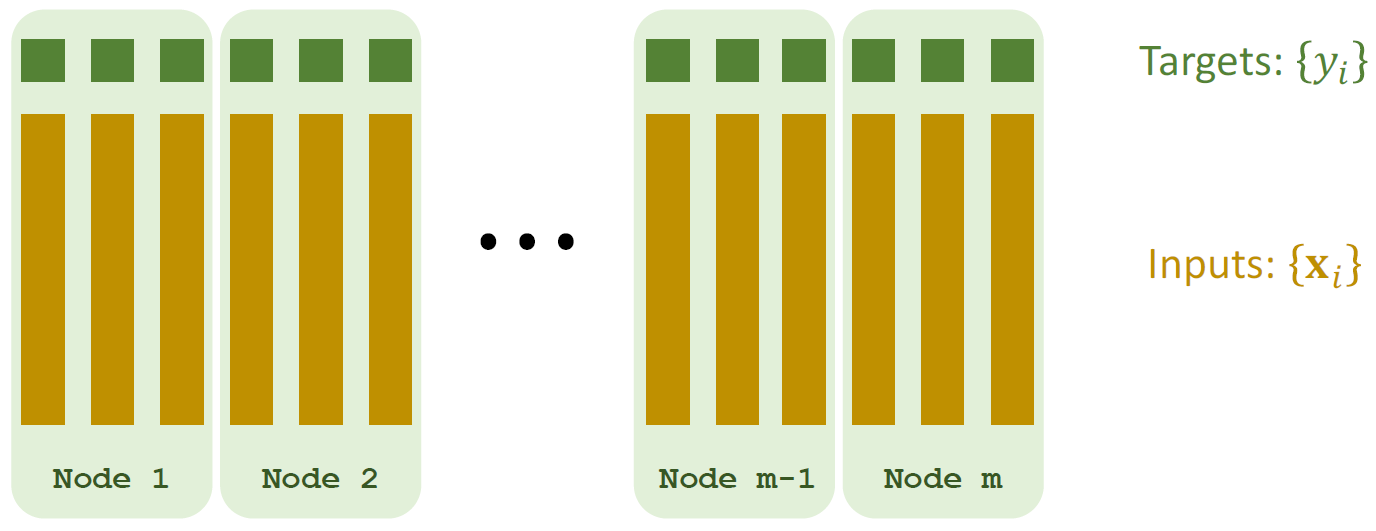
数据并行 Data Parallelism:在Worker节点之间划分数据(节点具有数据子集) 在本例中,我们假设有\(m\)个节点,因此将数据分成\(m\)份,每个节点拥有\(\frac{1}{m}\)数据
Broadcast:Server广播最新的模型参数\(W_t\)到各个Worker节点Map:Worker在本地执行计算任务- 将\((X_i, y_i, W_t)\)映射到\(g_i = (X^T_i W_t - y_i)X_i\)
- 获得\(n\)个梯度向量:\(g_i, \cdots, g_n\)(\(n\)是指样本个数)
Reduce:计算梯度和\(g = \sum^n_{i=1} g_i\)- Worker在本地将自己计算出的梯度进行求和得到一个向量
- Server根据每个Worker计算出的向量再进行一次求和
Update:Server更新参数 \(W_{t+1} \leftarrow W_t - \alpha \cdot g\)
时间消耗
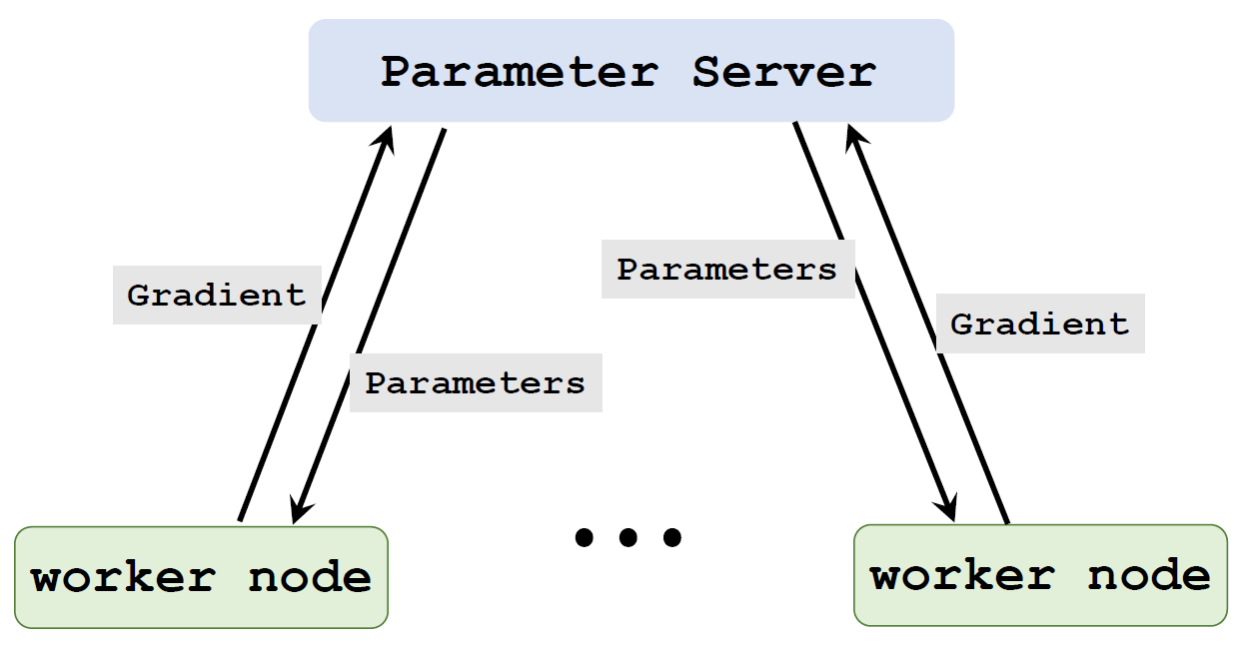
Parameter Server
在Scaling distributed machine learning with the parameter server中被提出,
- 本质思想:根据每个Worker传回的数据立即进行参数更新,即异步
- 开源实现:Ray
框架特点
- 架构:client-server
- 通信:消息传递
- 并行方式:异步
梯度下降
同样的,数据被划成\(m\)个子集分到每个Worker节点
第\(i\)个Worker节点重复:
- 从Server拉取最新参数\(W\)
- 利用本地数据和参数\(W\)计算梯度\(\tilde{g}_i\)
- 将梯度推送到Server
Server执行:
- 从一个Worker收到梯度\(\tilde{g}_i\)
- 参数更新\(W \leftarrow W - \alpha \cdot \tilde{g}_i\)
时间消耗
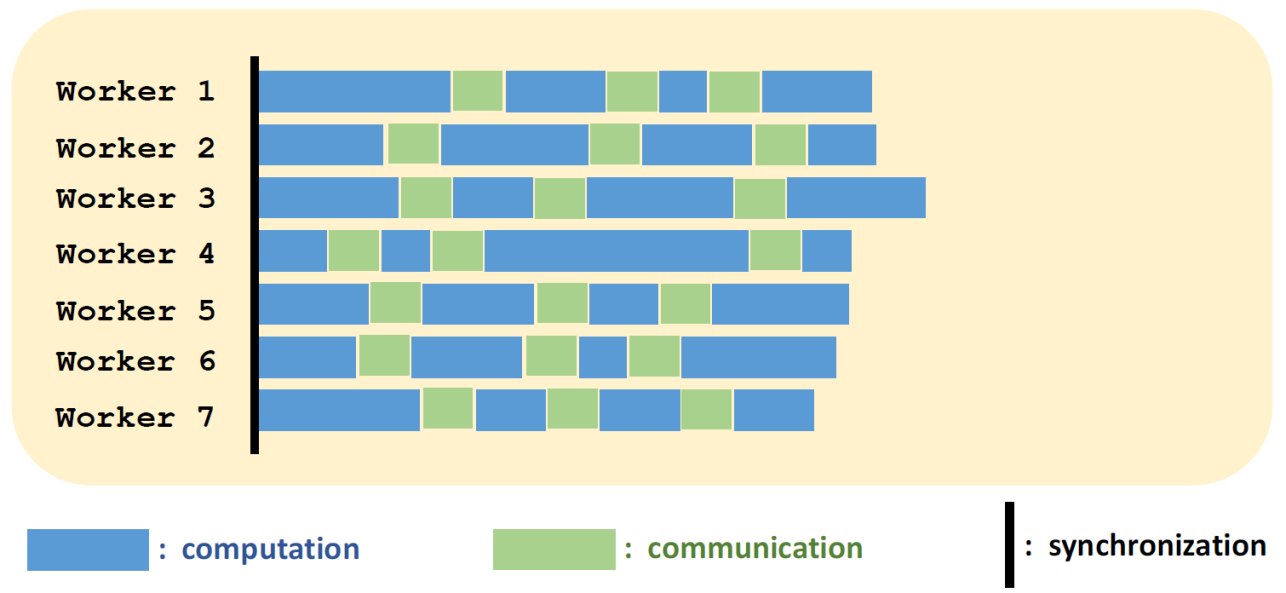
性能分析
优点
- 比同步的MapReduce更快
缺点
- 理论上,收敛速度更慢
- 如果某些节点比其他节点慢很多,梯度可能受损
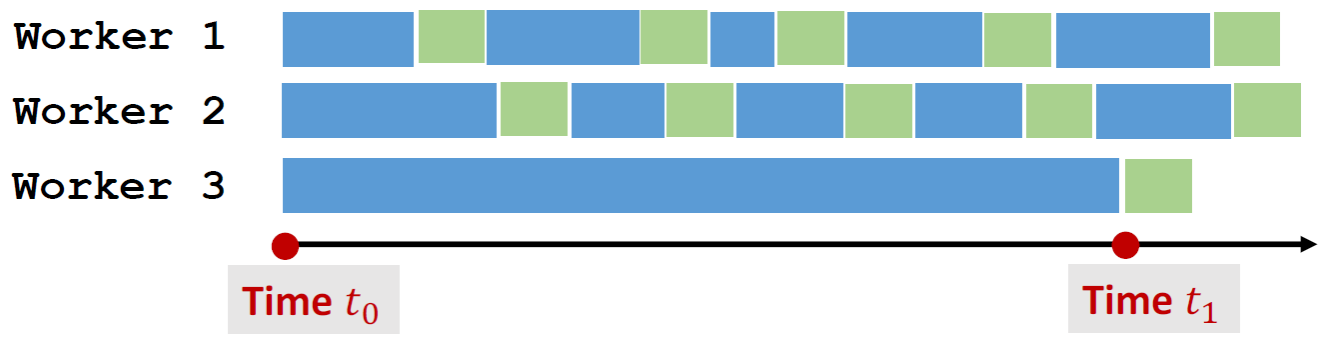
图示:Wroker 3 在\(t_1\)时刻才完成了一次梯度计算,并返回Server进行更新。而此时Server的参数已经被Worker 1 和 2 的梯度更新了数次,该梯度可能是不利于模型性能的
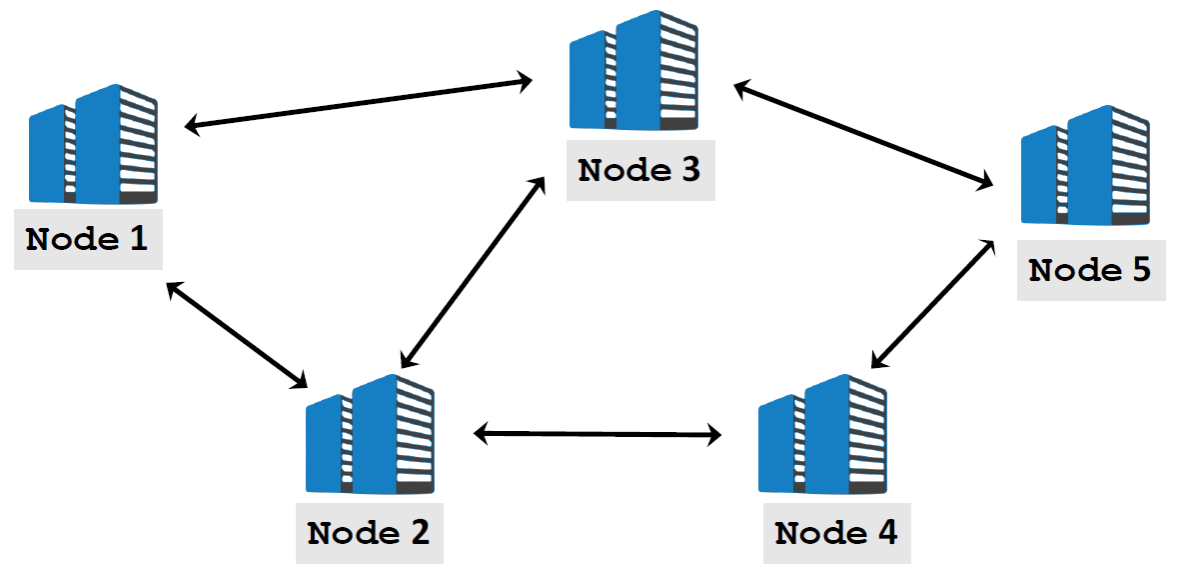
Decentralized Network
框架特点
- 架构:P2P
- 通信:消息传递,且节点只与其邻居进行通信
- 并行方式:异步或同步
梯度下降
第\(i\)个节点重复执行
- 使用本地参数\(\tilde{W_t}\)来计算梯度\(\tilde{g_t}\)
- 拉取邻居节点的梯度,表示为\(\{\tilde{W_k}\}\)
- 计算梯度平均值 \(\tilde{W} \leftarrow \text{weighted average of } \tilde{W_i} \text{ and } \{\tilde{W_k}\}\)
- 更新参数 \(\tilde{W} \leftarrow \tilde{W} - \alpha \cdot \tilde{g}_i\)
性能分析
被证明是可收敛的,但收敛情况取决于网络的连接情况
- 当网络的连接率是较好的时候,模型可以很快收敛
- 当节点间连接较少时,它可能不收敛

参考
Shusen Wang《分布式机器学习》
李哲龙. 分布式机器学习里的 数据并行 和 模型并行 各是什么意思? 知乎
Jeru Luke. Geo-Distributed Machine Learning: An Overview. Medium
Li and others: Scaling distributed machine learning with the parameter server. In OSDI, 2014.